役職名や部門名などの非構造化データは、マーケティングや営業活動の効果を阻害する大きな要因となります。本記事では、AIエージェントを活用してこれらのデータを自動で構造化し、CRM運用を効率化する方法を解説します。

よくある課題
非統一なデータの影響
「営業部」「販売部」「アカウントマネジメント部」など、同じ役割でも名称がバラバラなまま蓄積されていると、正確な分析やターゲティングが困難になります。
手動分類の非効率性
人手による分類・集計には時間と労力がかかり、入力漏れやミスも発生しやすくなります。
役職名や部門名のように、企業ごとに呼び方が異なる情報が非構造化データのまま保存されていると、レポーティングやマーケティング施策の精度に大きな影響が出ます。
例えば、営業部門向けのメール配信キャンペーンを行いたい場合でも、データベース内の部署名が統一されていないと、正しく「営業部門だけ」を抽出することができません。
これは、各社が独自の組織構造や文化を反映した部署名を用いていることが主な原因です。
営業部
販売部
アカウントマネジメント部
…など
こうした非構造化データを、人手で読み解きながら統一ルールに変換していく作業は、非常に負荷が高く、ミスも避けられません。本来なら人が判断しなくてよい反復作業を、AIエージェントに任せるべき領域です。
解決方法:AIを活用したデータ自動分類
この課題に対して、以下のツール構成で「非構造化データ → 構造化データ」への自動変換を実現します。
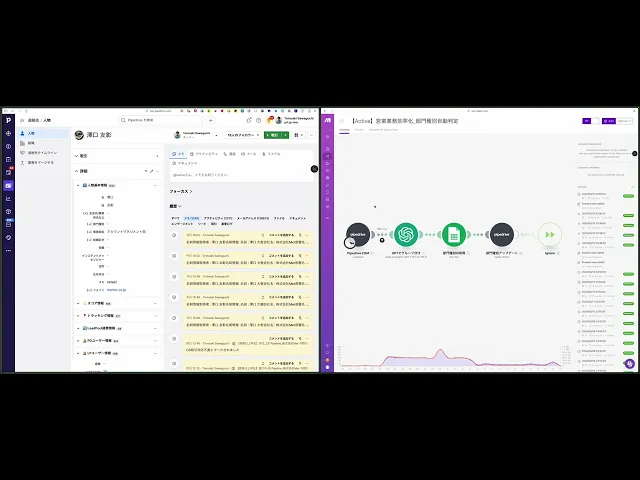
利用するツール
CRM / SFA:Pipedrive(部署・役職などのマスターデータ管理)
iPaaS:Make(データフローの自動化)
生成AI:ChatGPT(部署名・役職名の自動判定と分類)
ワークフロー概要
未分類データの取得
Pipedrive上で「部署種別」などの分類フィールドが未入力のレコードだけを抽出します。AIによる自動分類
ChatGPTに部署名などのテキストを渡し、「営業部門」「バックオフィス」「経営層」といったカテゴリに自動分類します。データの更新
判定結果をMake経由でPipedriveに書き戻し、分類フィールドを更新します。
自動化のメリット
作業時間の大幅削減
手作業での目視チェック・分類をほぼゼロにし、担当者の工数を圧縮します。データ活用のしやすさ向上
部門名や役職が統一された構造化データになることで、セグメント配信やレポートの精度が大きく上がります。人的ミスの削減
ルールベース+AI判定により、属人的な判断や入力ミスを最小限に抑えられます。
導入効果
この仕組みを導入することで、次のような効果が期待できます。
短時間で正確なデータ分類:大量レコードでも、自動で一括処理が可能
分析・施策の精度向上:構造化されたデータにより、ターゲティングやレポートがブレにくくなる
現場の負荷軽減:オペレーションの手間を削り、より付加価値の高い業務に時間を割ける
まとめ
AIエージェントと自動化ツールを組み合わせたこのプロセスは、CRMデータの精度を高めるだけでなく、マーケティング・営業施策の成果最大化にも直結します。
これまで人が根気よく対応していたデータ分類の作業を仕組み化することで、組織全体の生産性向上につながります。
CRMデータの整備と活用を本気で進めるうえでは、AIエージェントとiPaaSを前提とした運用設計が鍵になります。
こうした自動化プロセスの設計・実装は、diverにお任せください。業務要件の整理からフロー設計、運用定着まで、一気通貫でご支援します。


